Method
Proprioception-Based Two-Stage Training Framework
We introduce a two-stage training framework that relies solely on proprioception, enabling a robust policy that successfully passes tiny traps in both simulation and real-world environments. In the first stage, all the information can be accessed by the robot. We adopt an explicit-implicit dual-state learning. We also introduce a classifier head to guide the policy in learning the connection between the contact force distribution and the trap category. In the second stage, only goal command and proprioception can be observed. We initialize the weight of the estimator and the low-level RNN copied from the first training step. Probability Annealing Selection is used to gradually adapt policies to inaccurate estimates while reducing the degradation of the Oracle policy performance.
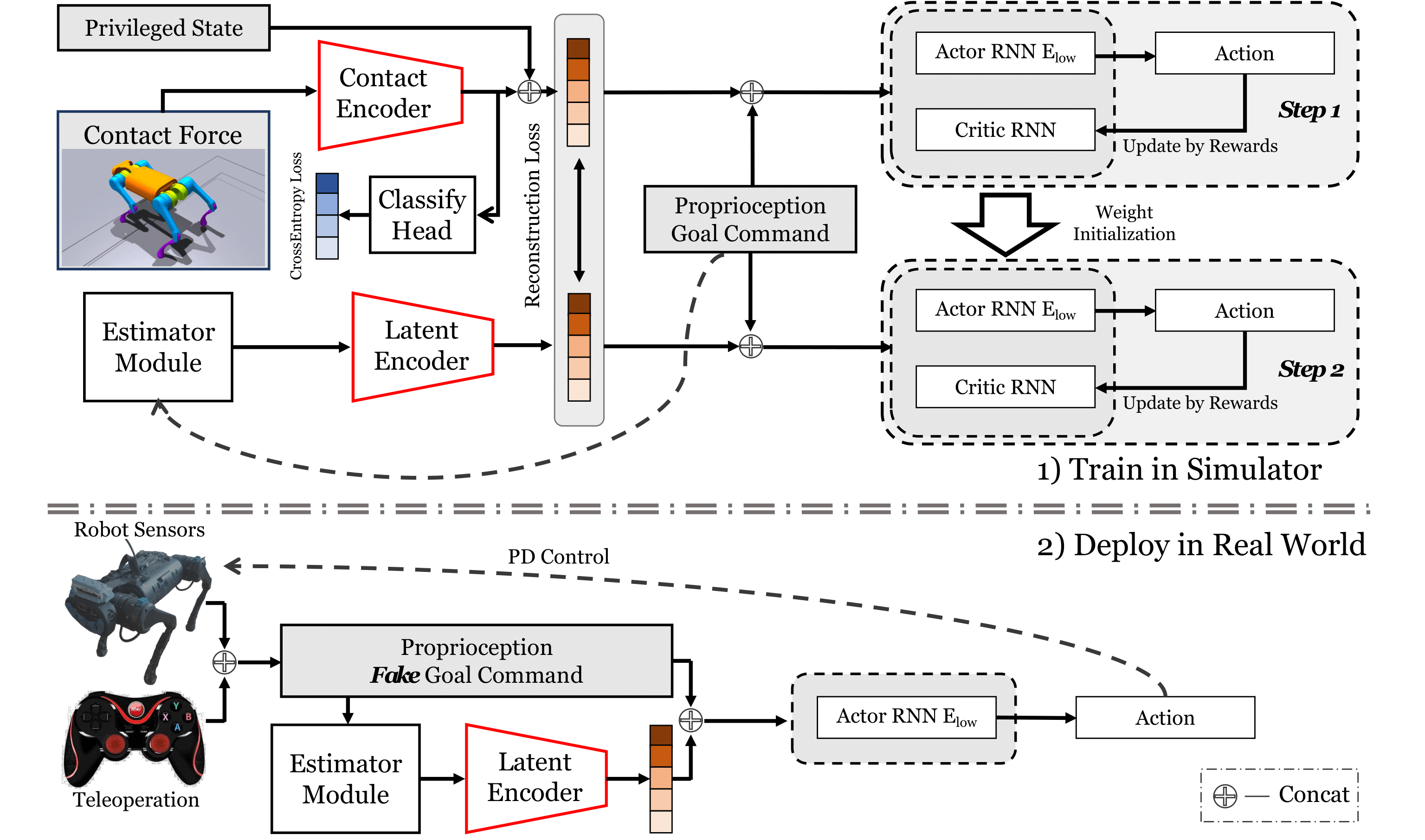
Explicit-Implicit Dual-State Estimation Paradigm
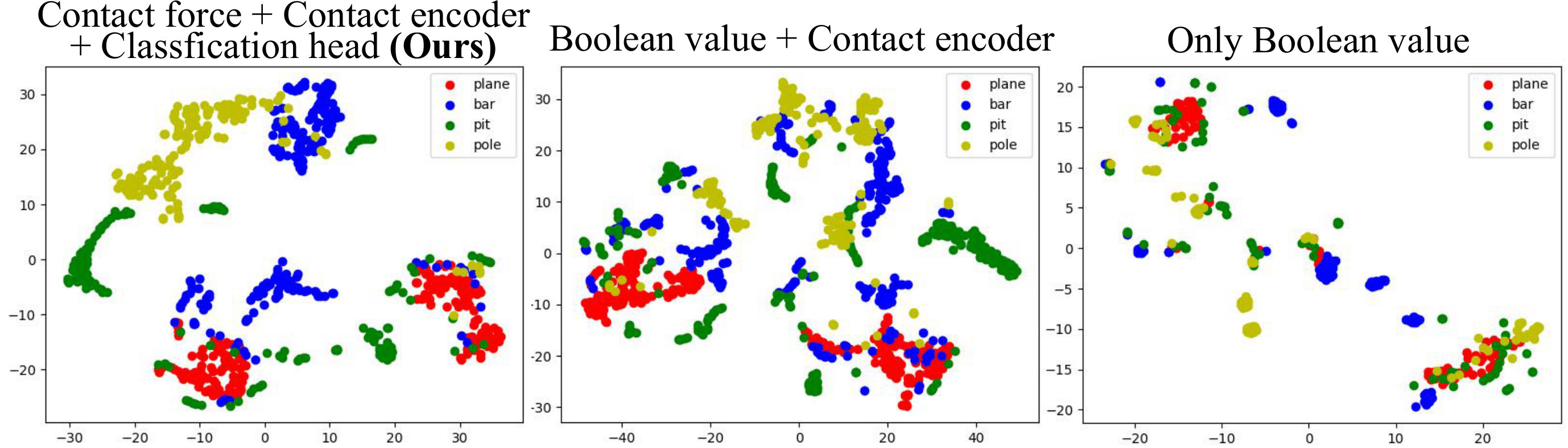
In the first state of training, the contact force is first encoded by a contact encoder to an implicit latent, and concatenated with explicit privileged state to the dual-state. In the second step of training, the dual state is predicted by the estimator. Without the explicit-implicit dual-state estimation paradigm, the robot will easily misjudge the current state, leading to ineliminable sim-to-real gaps. We employ t-SNE visualization to illustrate the noise-robust latent features learned through the explicit-implicit dual-state estimation paradigm.

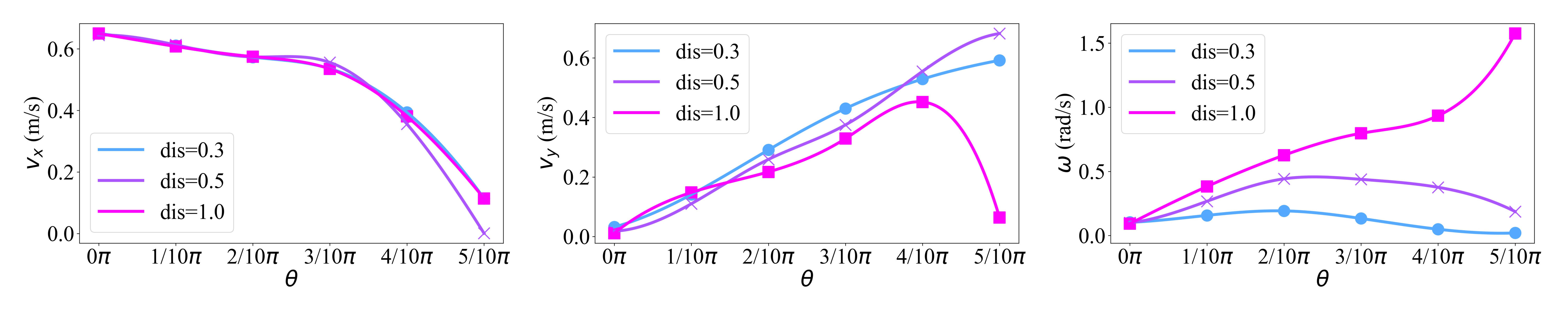
Goal Tracking
We redefine the task as goal tracking, rather than velocity tracking, and incorporate carefully designed dense reward functions and fake goal commands. This approach achieves approximate omnidirectional movement without motion capture or additional localization techniques in real-world, significantly improving training stability and adaptability across environments.